
この記事を三行にまとめると
関数の作成トリガーの設定
フェイルオーバーもできるよ
AWSのAuroraにはauto scalingの機能が備わってますが、現時点ではポリシーで設定できるのが平均CPU使用率か平均接続数の2つだけです。EC2のauto scalingみたいに時間で指定することができない。
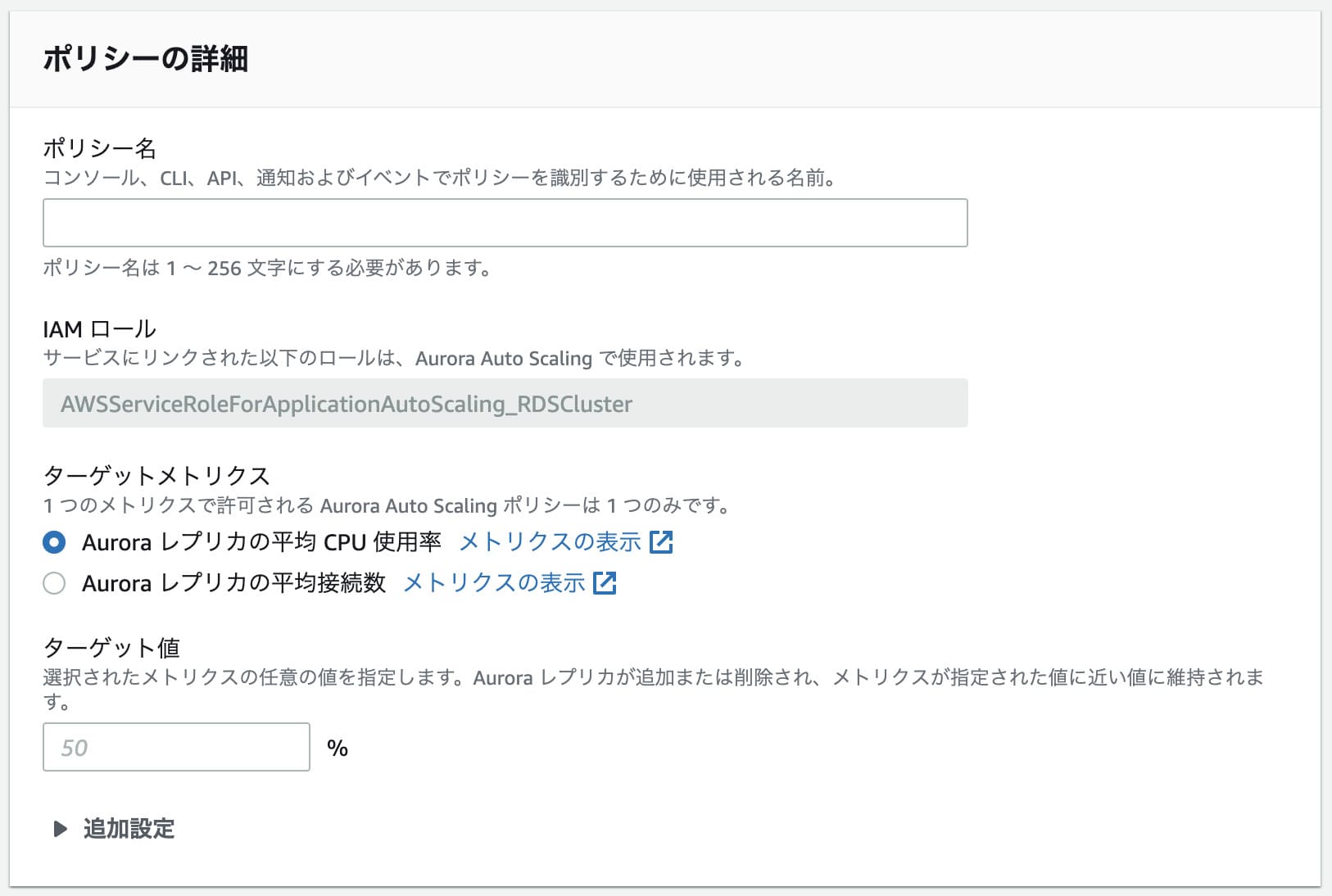
だから例えばアクセスの多い日中に一台増やして夜中になったら削除みたいな設定はここからではできないんですね。
じゃあそれをやりたい場合はどうするか。
AWS CLIコマンドを使ってもできるっぽいんですが、今回はLambdaを使って日時でリーダーの追加と削除を行えるようにしてみたいと思います。
Lambdaを開いて関数の作成ボタンを押し「一から作成」を選択するとこんな感じの入力画面が出てきます。
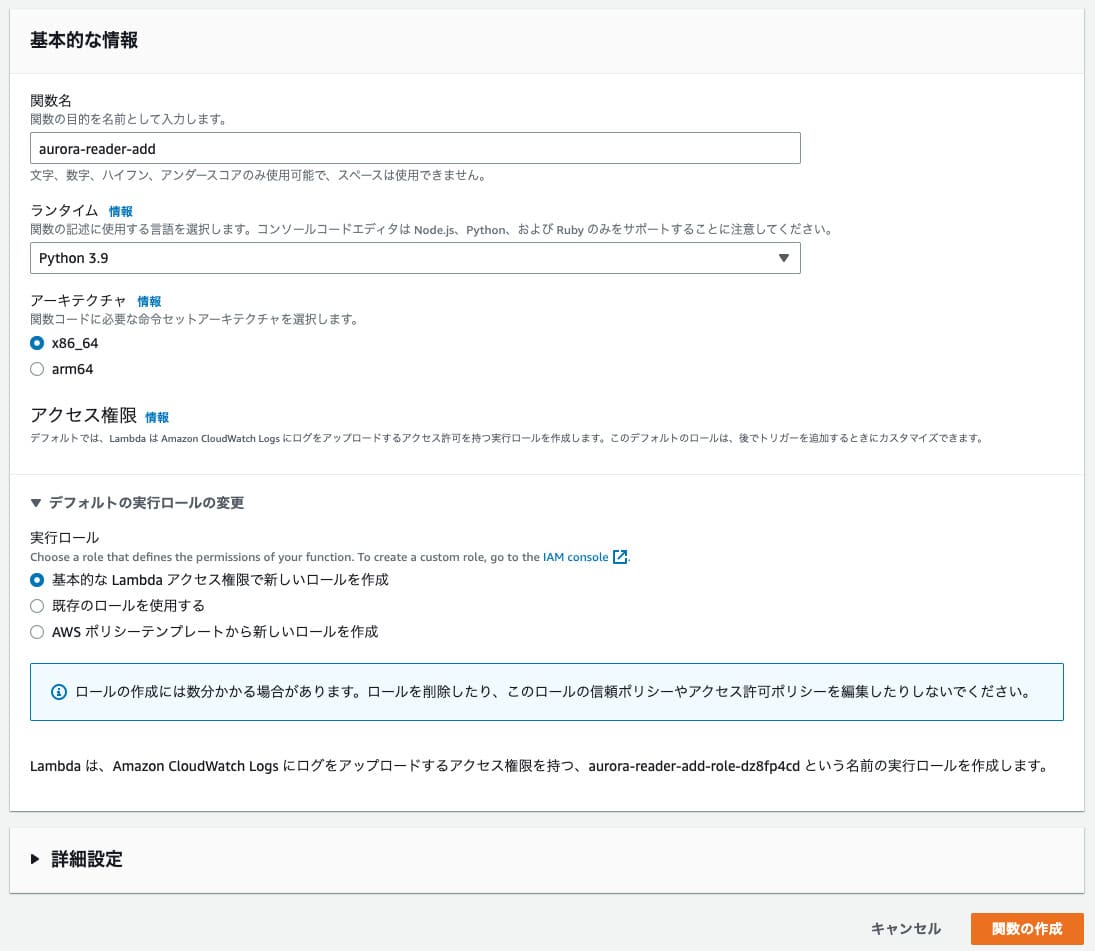
関数名は何でも良いです。ここでは「aurora-reader-add」としておきましょう。
ランタイムってのは関数を書く言語です。今回はPythonで関数を作成することにします。
あとは実行ロールの変更とか詳細設定の項目がありますが、そのままスルーして関数の作成ボタンを押してOKです。
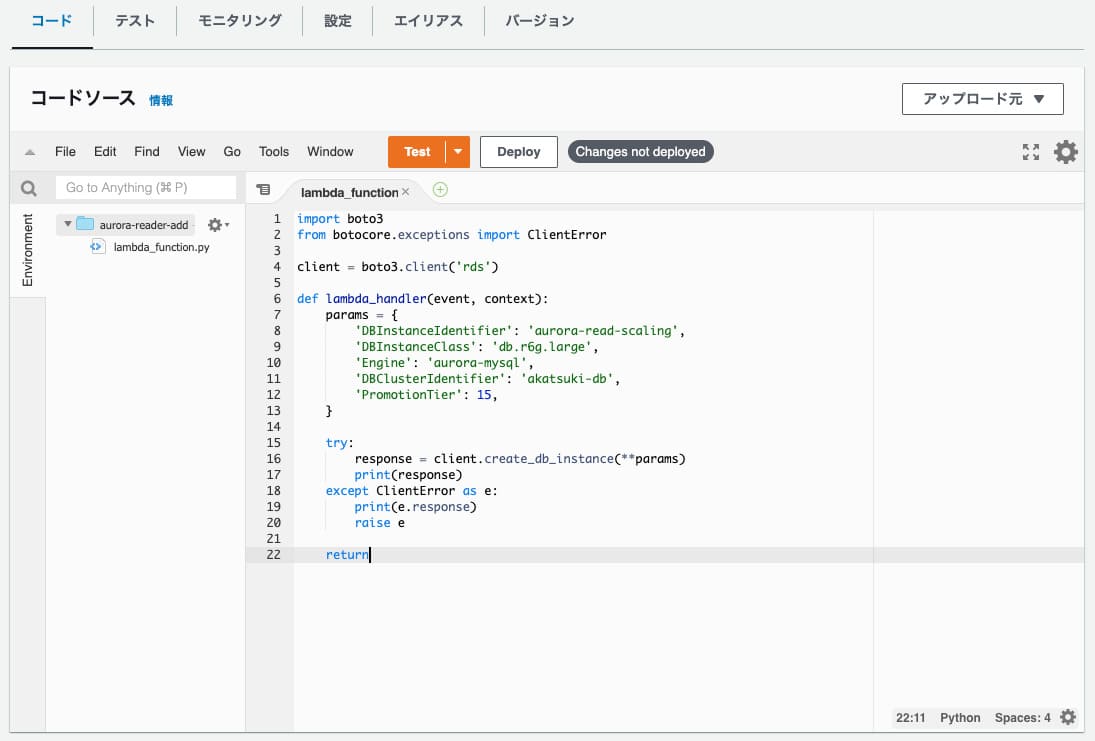
上の画像ではすでにコードが書いてあるのですが、これがリーダーを追加するための関数です。これを自分で記述することになります。
ざっくり言うと「create_db_instance」がインスタンスを新規に作成する関数です。
DBInstanceIdentifierはリーダーの名前です。これは通常のリーダー追加の時の「DBインスタンス識別子」のことです。一意である必要があります。
DBInstanceClassはインスタンスのクラスです。
Engineはデータベースのエンジンです。MySQLの場合は「aurora-mysql」と書きます。「mysql」とだけ書けばOKという記事を結構見かけるのですが、僕がやった時は「aurora-mysql」と書かないとエラーになったので、仕様が変わったのかもしれません。
DBClusterIdentifierはDBのクラスターの識別子です。どのクラスターに追加するかをここで指定します。
PromotionTierはフェイルオーバーの優先順位です。0〜15の範囲で指定します。数字が小さいほど優先順位が高く、フェイルオーバー時に優先的にライターインスタンスに置き換わります。ここでは15としているので優先順位は一番低い設定ですね。他にリーダーがある場合はそっちが優先的にライターになります。
コードを書き終わったら入力画面の上にある「Deploy」のボタンを押してデプロイすれば準備完了です。
RDSに関する権限の追加
コードをデプロイしたらこの関数にRDSへのアクセス権限を付与したいので、設定画面を開いて左メニューから「権限」を選択します。
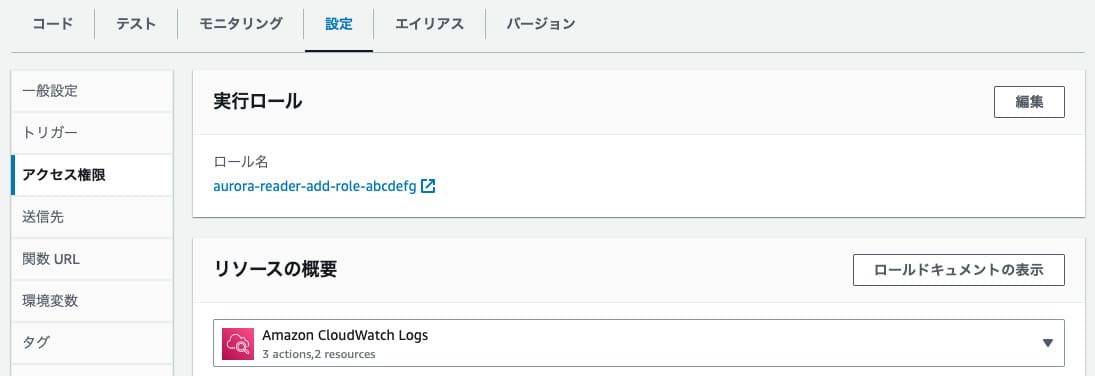
するとロール名ってのが出てくるので、これをクリックしてIAMのロール設定画面に飛び、許可を追加ボタンから「ポリシーをアタッチ」を選択します。
ここで検索ボックスに「RDS」と入力するとRDSに関するポリシーがいろいろ出てくるので「AmazonRDSFullAccess」のポリシーをアタッチします。これでとりあえずRDSに関する全ての操作権限をこのロールに付与できた状態になります。
イベント名は何でも良いです。むしろ何も入力しなくても良いです。それから今回は返り値とかはあまり関係がないので、テンプレートやイベントJSONもたぶん何でも良いです。なのでデフォルトのままイベント名だけ入力してテストボタンを押せば「create_db_instance」が即実行されてリーダーが追加されるはずです。
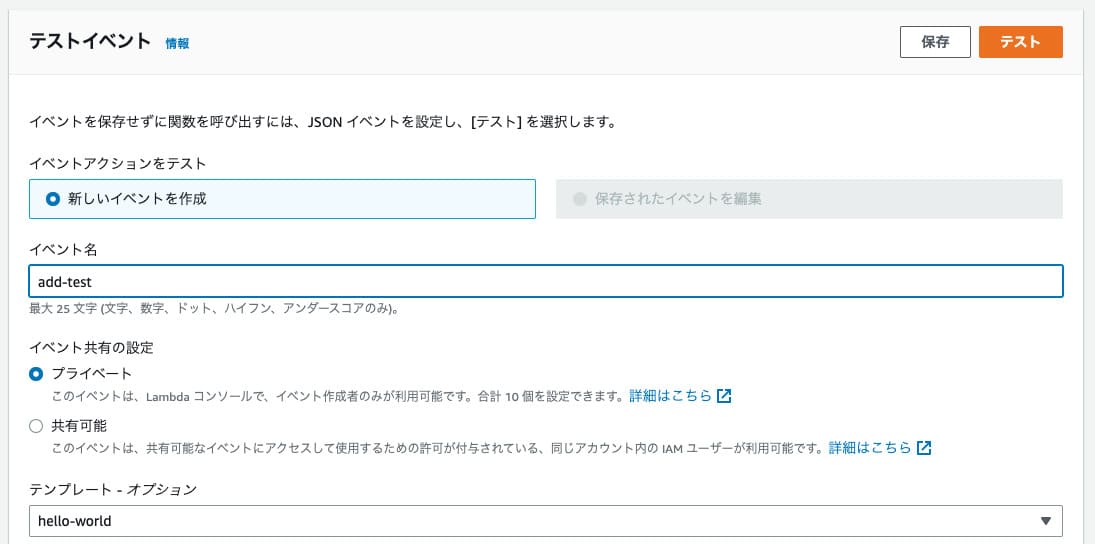
もしエラーが出た場合にはコードのタブのところにエラーログなどが出てくるので、それを見ればエラーの原因が分かります。
Cronの設定をするには関数の概要のところから「トリガーの追加」を選択します。
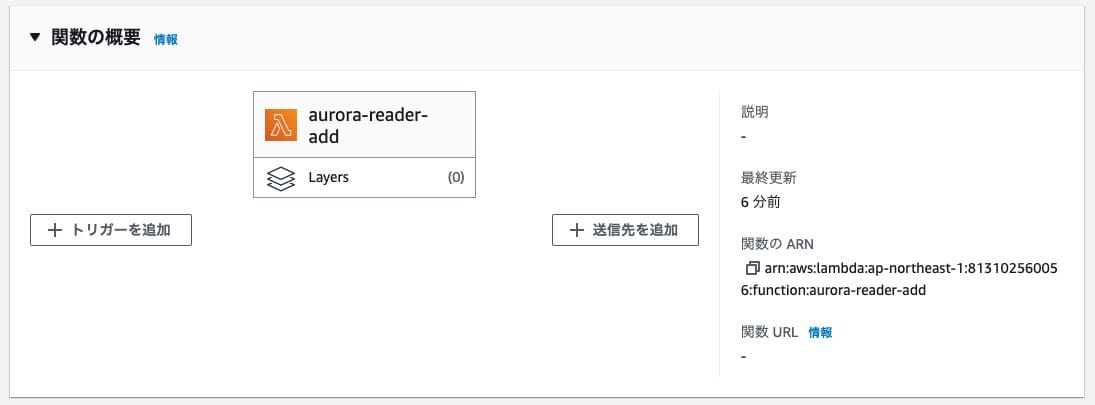
トリガーの追加を選択するとトリガーの設定画面が出てくるので、ソースの選択から「EventBridge」を選びます。
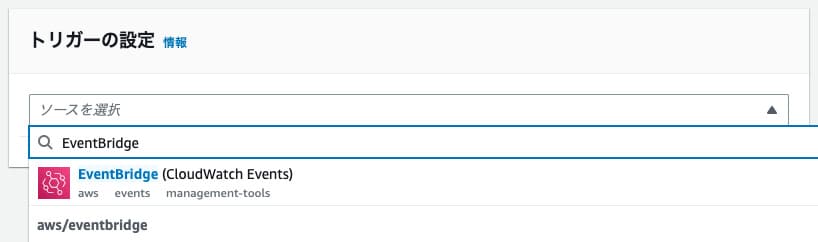
あとは新規ルールを作成でルール名を入力し、ルールタイプをスケジュール式にしてCron式を入力します。
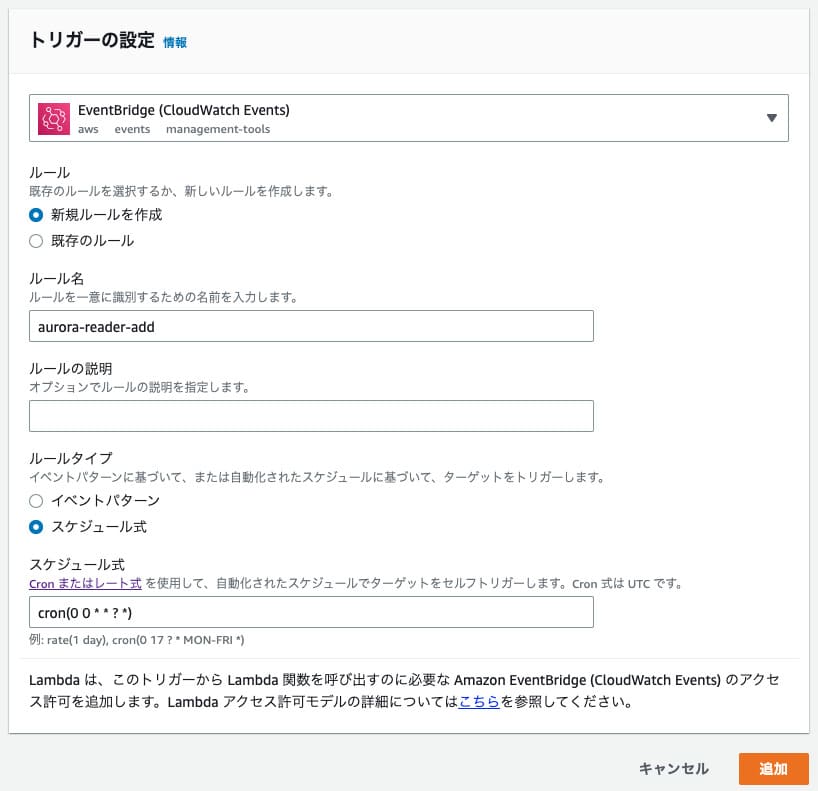
上記の画像の場合は「cron(0 0 * * ? *)」となっていますので、これは毎日0時ちょうどにリーダーの追加を実行するという設定になります。ただしこれはUTC時間(世界の標準時刻)なので、日本時間に直すと午前9時に実行ということになります。もし日本時間で0時に実行したい場合は「cron(0 15 * * ? *)」のように書く必要があります。
関数の作成や権限の付与、定期実行の設定については上記のやり方と全く同じ手順を行えば良いので、ここでは削除のためのコードだけ記述します。
リーダーを削除するには以下の処理をPythonで書けばOKです。
「delete_db_instance」がインスタンスを削除するための関数です。これでDBInstanceIdentifierで指定したインスタンスが削除されます。
インスタンスが一つしかない状態で削除するとクラスターも一緒に削除されますが、この削除処理をRDSのコンソールから行うと最終スナップショットを残すかどうか訊かれますよね。この最終スナップショットを残すかどうかの設定はSkipFinalSnapshotで指定します。残さなくて良い場合はTrueにします。
以上がAuroraの時間指定によるスケーリングの処理です。
時間指定によるスケーリングって結構需要があると思うのでそのうちRDSのコンソールから設定できるようになるんじゃないかって気もするんですが、とりあえず今はできないので、日中だけリーダーを追加したいみたいなときはこの方法を試してみてください。
ちなみにフェイルオーバーもLambdaで行うことができるので、リーダーを作成した後にそれをライターインスタンスに入れ替えることもできます。
だから例えばアクセスの多い日中に一台増やして夜中になったら削除みたいな設定はここからではできないんですね。
じゃあそれをやりたい場合はどうするか。
AWS CLIコマンドを使ってもできるっぽいんですが、今回はLambdaを使って日時でリーダーの追加と削除を行えるようにしてみたいと思います。
関数の作成
まずはLambdaでリーダーを追加するための関数を作成します。Lambdaを開いて関数の作成ボタンを押し「一から作成」を選択するとこんな感じの入力画面が出てきます。
関数名は何でも良いです。ここでは「aurora-reader-add」としておきましょう。
ランタイムってのは関数を書く言語です。今回はPythonで関数を作成することにします。
あとは実行ロールの変更とか詳細設定の項目がありますが、そのままスルーして関数の作成ボタンを押してOKです。
コードを書く
無事に関数の作成が完了するとコードの入力画面が出てきます。上の画像ではすでにコードが書いてあるのですが、これがリーダーを追加するための関数です。これを自分で記述することになります。
import boto3
from botocore.exceptions import ClientError
client = boto3.client('rds')
def lambda_handler(event, context):
params = {
'DBInstanceIdentifier': 'aurora-read-scaling',
'DBInstanceClass': 'db.r6g.large',
'Engine': 'aurora-mysql',
'DBClusterIdentifier': 'akatsuki-db',
'PromotionTier': 15,
}
try:
response = client.create_db_instance(**params)
print(response)
except ClientError as e:
print(e.response)
raise e
return
ざっくり言うと「create_db_instance」がインスタンスを新規に作成する関数です。
DBInstanceIdentifierはリーダーの名前です。これは通常のリーダー追加の時の「DBインスタンス識別子」のことです。一意である必要があります。
DBInstanceClassはインスタンスのクラスです。
Engineはデータベースのエンジンです。MySQLの場合は「aurora-mysql」と書きます。「mysql」とだけ書けばOKという記事を結構見かけるのですが、僕がやった時は「aurora-mysql」と書かないとエラーになったので、仕様が変わったのかもしれません。
DBClusterIdentifierはDBのクラスターの識別子です。どのクラスターに追加するかをここで指定します。
PromotionTierはフェイルオーバーの優先順位です。0〜15の範囲で指定します。数字が小さいほど優先順位が高く、フェイルオーバー時に優先的にライターインスタンスに置き換わります。ここでは15としているので優先順位は一番低い設定ですね。他にリーダーがある場合はそっちが優先的にライターになります。
コードを書き終わったら入力画面の上にある「Deploy」のボタンを押してデプロイすれば準備完了です。
するとロール名ってのが出てくるので、これをクリックしてIAMのロール設定画面に飛び、許可を追加ボタンから「ポリシーをアタッチ」を選択します。
ここで検索ボックスに「RDS」と入力するとRDSに関するポリシーがいろいろ出てくるので「AmazonRDSFullAccess」のポリシーをアタッチします。これでとりあえずRDSに関する全ての操作権限をこのロールに付与できた状態になります。
その場で作成テストをしたい場合
デプロイ後すぐにリーダーの追加を実行したい場合はコードの隣にあるテストのタブを開いてテストイベントを作成します。イベント名は何でも良いです。むしろ何も入力しなくても良いです。それから今回は返り値とかはあまり関係がないので、テンプレートやイベントJSONもたぶん何でも良いです。なのでデフォルトのままイベント名だけ入力してテストボタンを押せば「create_db_instance」が即実行されてリーダーが追加されるはずです。
もしエラーが出た場合にはコードのタブのところにエラーログなどが出てくるので、それを見ればエラーの原因が分かります。
Cronで定期実行する
テストを実行して無事にリーダーが追加されたのであればコードは正常に動くということなので、次はCronで定期実行できるようにしてみます。Cronの設定をするには関数の概要のところから「トリガーの追加」を選択します。
トリガーの追加を選択するとトリガーの設定画面が出てくるので、ソースの選択から「EventBridge」を選びます。
あとは新規ルールを作成でルール名を入力し、ルールタイプをスケジュール式にしてCron式を入力します。
上記の画像の場合は「cron(0 0 * * ? *)」となっていますので、これは毎日0時ちょうどにリーダーの追加を実行するという設定になります。ただしこれはUTC時間(世界の標準時刻)なので、日本時間に直すと午前9時に実行ということになります。もし日本時間で0時に実行したい場合は「cron(0 15 * * ? *)」のように書く必要があります。
リーダーの削除
上記の設定が一通り完了すれば時間指定でのリーダーの追加処理は完了なので、続いてリーダーの削除処理の関数を追加します。関数の作成や権限の付与、定期実行の設定については上記のやり方と全く同じ手順を行えば良いので、ここでは削除のためのコードだけ記述します。
リーダーを削除するには以下の処理をPythonで書けばOKです。
import boto3
from botocore.exceptions import ClientError
client = boto3.client('rds')
def lambda_handler(event, context):
params = {
'DBInstanceIdentifier': 'aurora-read-scaling',
'SkipFinalSnapshot': True,
}
try:
response = client.delete_db_instance(**params)
print(response)
except ClientError as e:
print(e.response)
raise e
return「delete_db_instance」がインスタンスを削除するための関数です。これでDBInstanceIdentifierで指定したインスタンスが削除されます。
インスタンスが一つしかない状態で削除するとクラスターも一緒に削除されますが、この削除処理をRDSのコンソールから行うと最終スナップショットを残すかどうか訊かれますよね。この最終スナップショットを残すかどうかの設定はSkipFinalSnapshotで指定します。残さなくて良い場合はTrueにします。
以上がAuroraの時間指定によるスケーリングの処理です。
時間指定によるスケーリングって結構需要があると思うのでそのうちRDSのコンソールから設定できるようになるんじゃないかって気もするんですが、とりあえず今はできないので、日中だけリーダーを追加したいみたいなときはこの方法を試してみてください。
ちなみにフェイルオーバーもLambdaで行うことができるので、リーダーを作成した後にそれをライターインスタンスに入れ替えることもできます。
import boto3
from botocore.exceptions import ClientError
client = boto3.client('rds')
def lambda_handler(event, context):
params = {
'DBClusterIdentifier': 'akatsuki-db',
}
try:
response = client.failover_db_cluster(**params)
print(response)
except ClientError as e:
print(e.response)
raise e
return




