この記事を三行にまとめると
IAMロールとポリシーが必要KMSのカスタムキーも必要
S3で直接クエリを書いて検索できる
Aurora(MySQL)のデータのバックアップを取るためには主にスナップショットを作成するという方法がありますね。
でもこれだとDB丸ごとのバックアップしか取れない上、もしここから過去のデータを漁りたい場合にはスナップショットからDBを新規に作成して接続して調べるという手順を踏まないといけません。こいつが結構手間だったりする。DBが作成されるまで待ってなきゃいけないし、終わったら忘れずに削除しないと不要な費用が発生しちゃうし。
なのでMySQLでバックアップデータを取る際にはmysqldumpを使ってテーブル単位でSQLファイルを作成し、そいつをS3に保存しておく方が良いような気がするんですが、でもデータが少ないうちはこれでも良いんですけど、ある程度ボリュームが膨らんでくるとmysqldumpがいつまで経っても終わらないみたいな事態になったりして、それはそれで都合がよくない。
でも最近知ったんですけど、mysqldumpを使わなくてもRDSにはテーブル単位でS3にデータをエクスポートしてくれる機能があるんですね。以前はスナップショットのデータをS3にエクスポートする機能しかなかったようなんですが、今は稼働中のDBクラスターのデータをS3にエクスポートできるので、今回はこれを使ってAuroraのデータをS3に保存してみたいと思います。
今回はAuroraのDBと保存先のS3のバケットがすでにあるという前提で話しますので、AuroraやS3のバケットの作成方法についてはすみませんが別途ググったりジピったりしてください。
ジピる・・・ChatGPTさんに訊ねること。今適当に考えた。
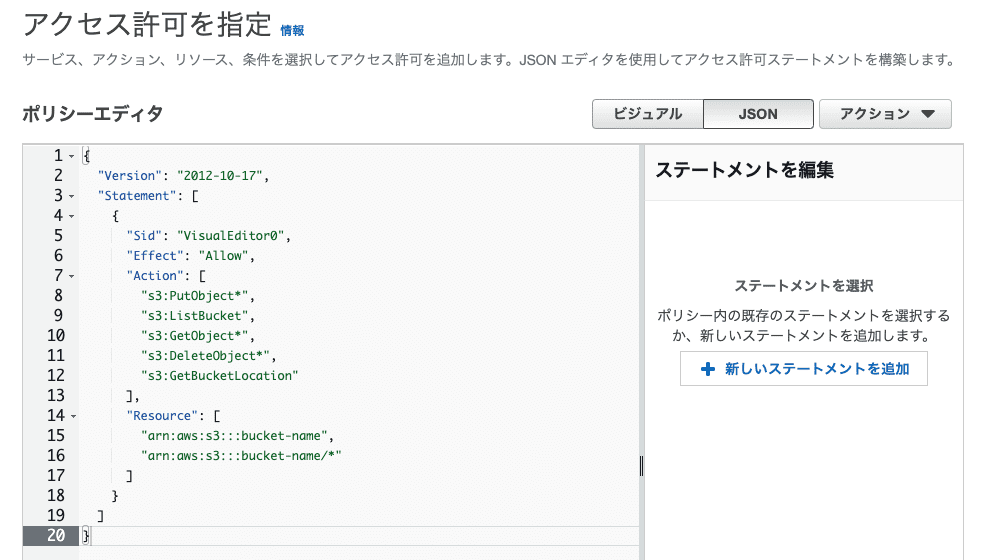
ポリシーの新規作成画面を開いたらビジュアルではなくJSONの入力画面に切り替えて以下のポリシーを記述します。
「bucket-name」のところには保存先のS3のバケット名を書きます。
あとは適当にポリシー名を入力してポリシーを作成します。
ポリシーが作成できたら今度はロールの新規作成画面を開きます。

カスタム信頼ポリシーを選択して以下のポリシーを記述します。
あとは許可ポリシーで先ほど作成したポリシーにチェックを入れて、適当にロール名を入力してロールの作成を完了します。
キー設定はデフォルトのままでOKです。エイリアス名も何でも良いです。
重要なのはキーユーザーのところで先ほど作成したロールを選択することです。
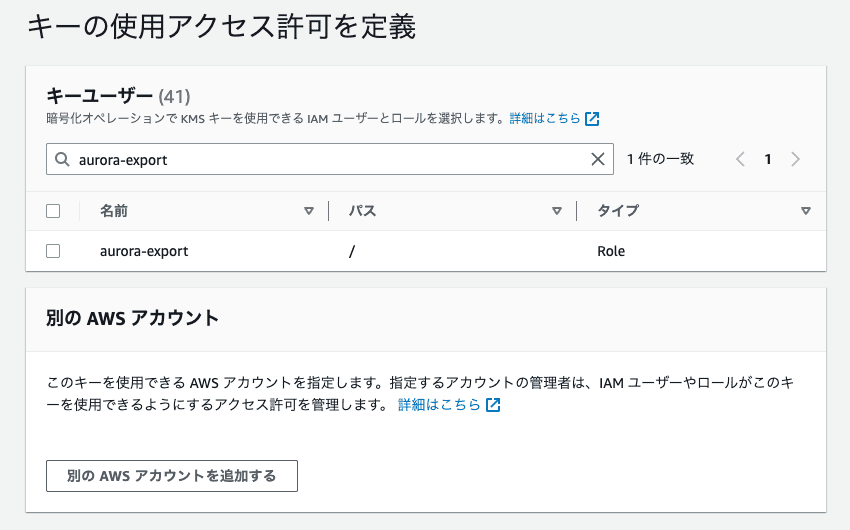
上の画像ではaurora-exportとなっていますが、これは僕が適当に作った名前なので、各自自分で作成したロール名を探してチェックを入れてください。
これでエクスポートを行う準備が整いました。
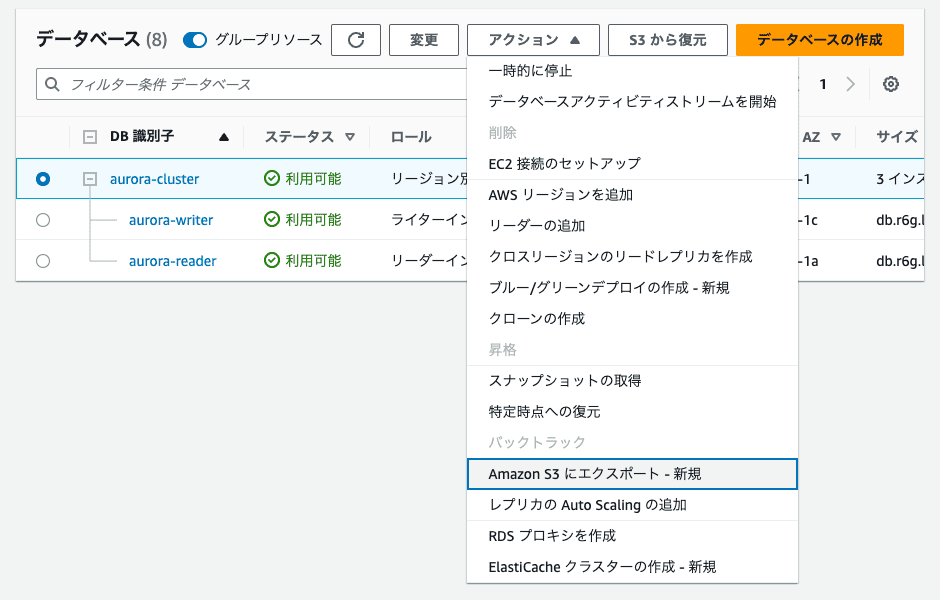
選択するとエクスポートに必要な設定画面が出てくるのでそれぞれ入力します。
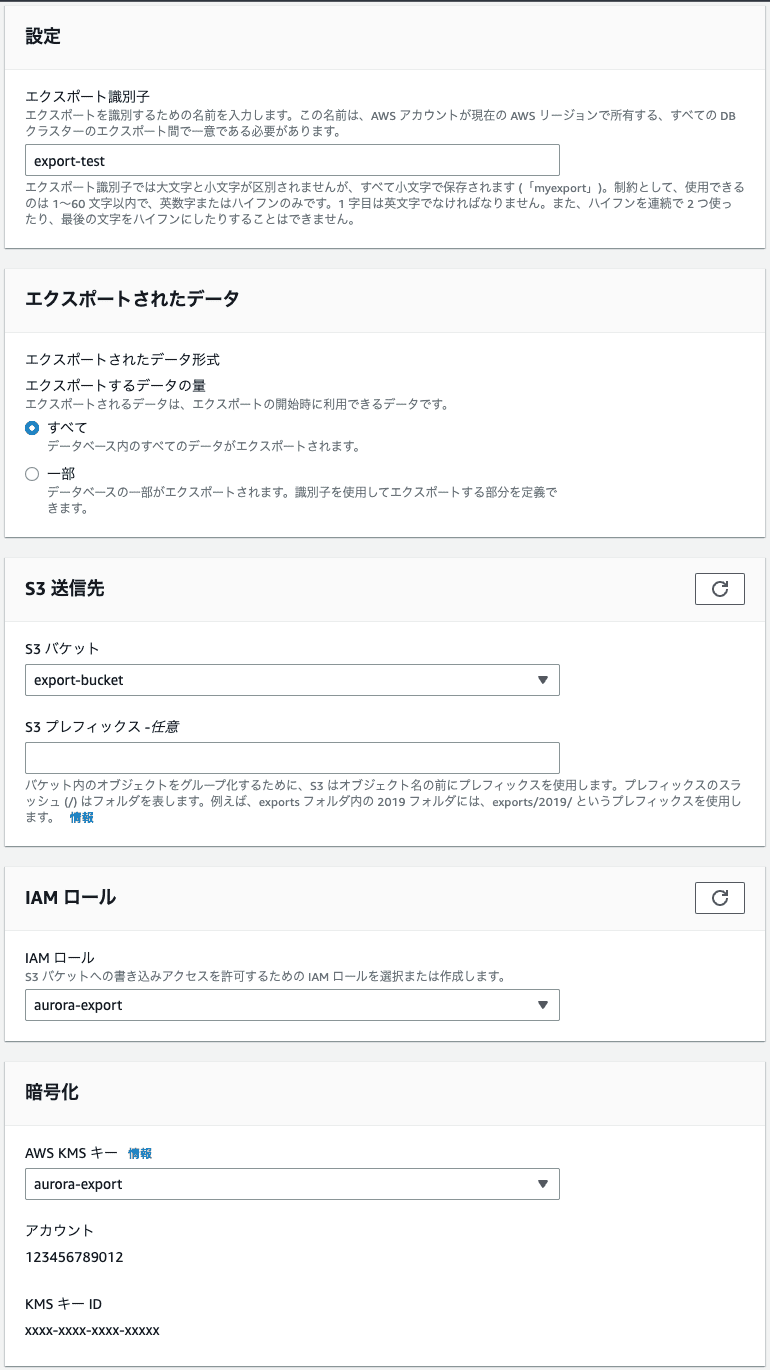
識別子は一意であれば何でも良いです。エクスポートされたデータは一部を選択すれば特定のテーブルだけをエクスポートしたりできます。
あとは保存先のS3のバケットを選択して必要ならプレフィックスを入力し、上記で作成したIAMのロールとKMSキーを選択してエクスポートボタンを押せばエクスポートが始まります。
エクスポートにかかる時間はデータの量によっても変わってくるみたいなんですが、僕がやったときは15〜30分くらいで完了しました。内部的にはクラスターのクローンを作成してそこからデータがエクスポートされるらしいので、このエクスポートによって稼働中のDBに負荷がかかる心配はないようです。
ちなみにIAMロールはあらかじめ作っておかなくてもここで「新しいロールの作成」を選択すればエクスポート時にロールが作成されるみたいなんですが、僕がやったときはエラーになってエクスポートが上手くいかなかったので、あらかじめ作っておいた方が良いと思います。ロールは確かに自動で作成されたんですけど、そのロールに必要なポリシーが適切にくっつかなかったとかそんな感じっぽかったです。
S3のデータを見てみる
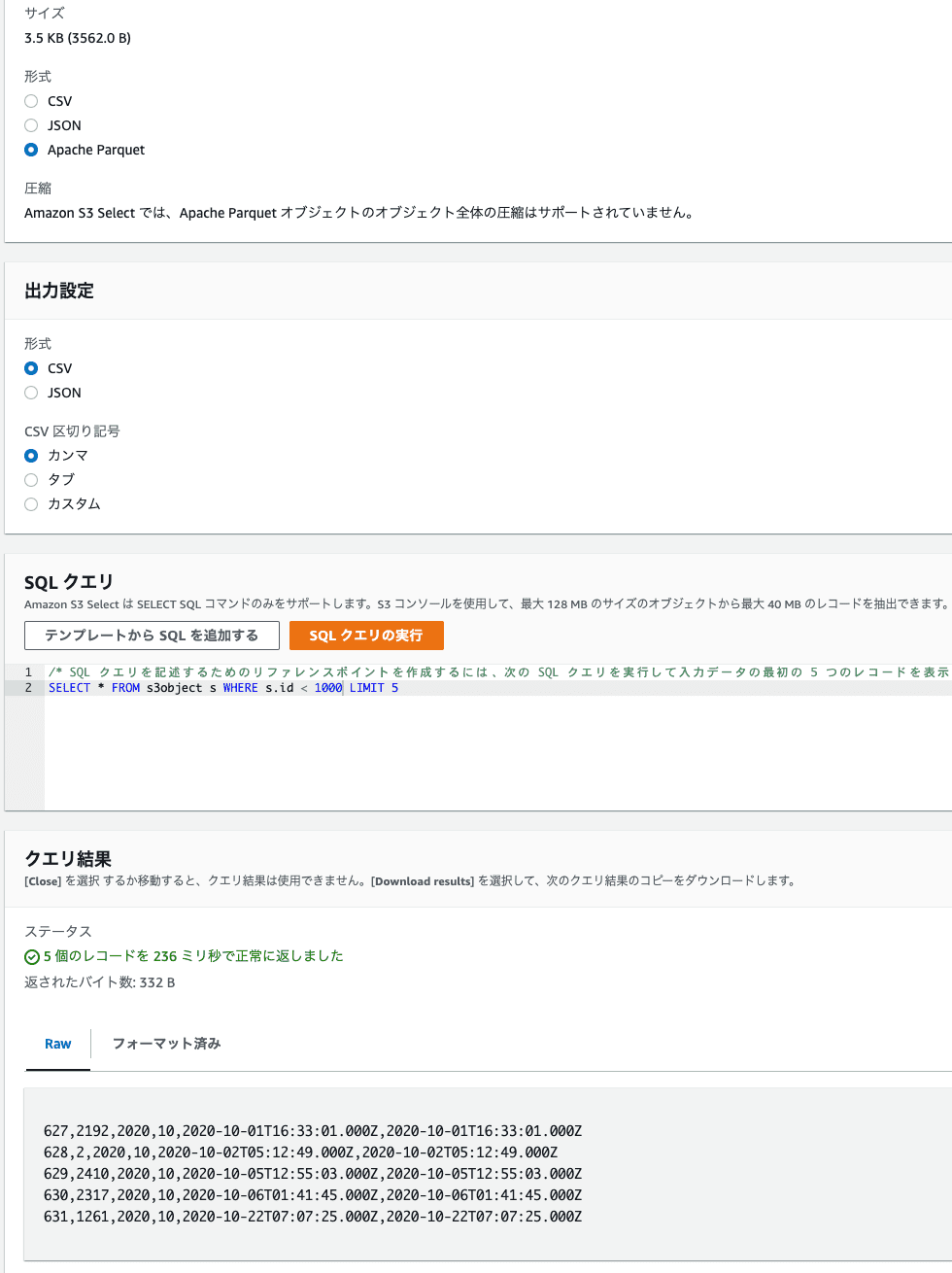
無事にエクスポートが終わるとS3のバケットに「xxx.parquet」という形式のファイルが保存されています。これはApache Parquetという形式のデータファイルで、このファイル自体はバイナリファイルなのでテキストエディタで開くにはいろいろ手間がかかるんですが、ファイルのオブジェクトアクションで「S3 Select を使用したクエリ」を選択すればS3の中で直接クエリを書いてデータを検索したりできます。
でもこれだとDB丸ごとのバックアップしか取れない上、もしここから過去のデータを漁りたい場合にはスナップショットからDBを新規に作成して接続して調べるという手順を踏まないといけません。こいつが結構手間だったりする。DBが作成されるまで待ってなきゃいけないし、終わったら忘れずに削除しないと不要な費用が発生しちゃうし。
なのでMySQLでバックアップデータを取る際にはmysqldumpを使ってテーブル単位でSQLファイルを作成し、そいつをS3に保存しておく方が良いような気がするんですが、でもデータが少ないうちはこれでも良いんですけど、ある程度ボリュームが膨らんでくるとmysqldumpがいつまで経っても終わらないみたいな事態になったりして、それはそれで都合がよくない。
でも最近知ったんですけど、mysqldumpを使わなくてもRDSにはテーブル単位でS3にデータをエクスポートしてくれる機能があるんですね。以前はスナップショットのデータをS3にエクスポートする機能しかなかったようなんですが、今は稼働中のDBクラスターのデータをS3にエクスポートできるので、今回はこれを使ってAuroraのデータをS3に保存してみたいと思います。
今回はAuroraのDBと保存先のS3のバケットがすでにあるという前提で話しますので、AuroraやS3のバケットの作成方法についてはすみませんが別途ググったりジピったりしてください。
ジピる・・・ChatGPTさんに訊ねること。今適当に考えた。
IAMのロールとポリシーを作成
エクスポートを行うためにはIAMのロールとポリシーが必要になりますが、ロールを作成する際に許可するポリシーの設定が必要になるので、まずはポリシーから作成します。ポリシーの新規作成画面を開いたらビジュアルではなくJSONの入力画面に切り替えて以下のポリシーを記述します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject*",
"s3:ListBucket",
"s3:GetObject*",
"s3:DeleteObject*",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::bucket-name",
"arn:aws:s3:::bucket-name/*"
]
}
]
}「bucket-name」のところには保存先のS3のバケット名を書きます。
あとは適当にポリシー名を入力してポリシーを作成します。
ポリシーが作成できたら今度はロールの新規作成画面を開きます。
カスタム信頼ポリシーを選択して以下のポリシーを記述します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "export.rds.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}あとは許可ポリシーで先ほど作成したポリシーにチェックを入れて、適当にロール名を入力してロールの作成を完了します。
KMSでカスタムキーを作成する
エクスポートを行うにはIAMのロール以外にKey Management Serviceのカスタムキーも必要になります。キー設定はデフォルトのままでOKです。エイリアス名も何でも良いです。
重要なのはキーユーザーのところで先ほど作成したロールを選択することです。
上の画像ではaurora-exportとなっていますが、これは僕が適当に作った名前なので、各自自分で作成したロール名を探してチェックを入れてください。
これでエクスポートを行う準備が整いました。
実際にエクスポートしてみる
RDSのクラスターを選択するとアクションの中に「Amazon S3にエクスポート」という項目があるのでこれを選択します。選択するとエクスポートに必要な設定画面が出てくるのでそれぞれ入力します。
識別子は一意であれば何でも良いです。エクスポートされたデータは一部を選択すれば特定のテーブルだけをエクスポートしたりできます。
あとは保存先のS3のバケットを選択して必要ならプレフィックスを入力し、上記で作成したIAMのロールとKMSキーを選択してエクスポートボタンを押せばエクスポートが始まります。
エクスポートにかかる時間はデータの量によっても変わってくるみたいなんですが、僕がやったときは15〜30分くらいで完了しました。内部的にはクラスターのクローンを作成してそこからデータがエクスポートされるらしいので、このエクスポートによって稼働中のDBに負荷がかかる心配はないようです。
ちなみにIAMロールはあらかじめ作っておかなくてもここで「新しいロールの作成」を選択すればエクスポート時にロールが作成されるみたいなんですが、僕がやったときはエラーになってエクスポートが上手くいかなかったので、あらかじめ作っておいた方が良いと思います。ロールは確かに自動で作成されたんですけど、そのロールに必要なポリシーが適切にくっつかなかったとかそんな感じっぽかったです。